Right now our discovery and import attempts to find a process and get all the information from it, then presents the results to the user in the import queue from where it can be taken into inventory and child discovery happens.
The following graph tries to illustrate this:
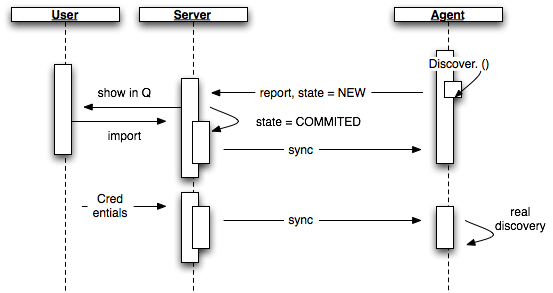
In reality that approach has its issues:
-
To obtain version info etc. it is often necessary to talk via some interface to the resource, which means passing credentials, which are not yet given at discovery time
-
as7-api needs credentials
-
jmx-servers needs credentials
-
-
The user can not select a (preferred) way of discovery - e.g. use of ssl or not
-
The user can't verify on import if some properties of a resource is correct - e.g. it is not possible to present a server side ssl certificate to acknowledge at import time
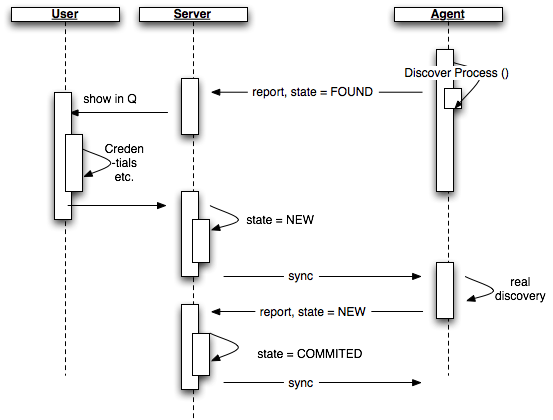
2-phase discovery
So the idea is to have a 2-phase approach, where in the 1st phase we merely find the process (+ additional info) and then present that to the user. The user can verify certificates, pass credentials select http vs. https and then clicks on import. The server will then tell the agent to run the discovery (basically as it works today) with those existing credentials
Why?
The big benefit is that a discovery with credentials can get certain values right from the start via api-calls, so that a lot of "external" code to work around the missing credentials can go away.
Also for the new feature of discovering foo-1.war and foo-2.war both as foo.war with version 1 and 2 respectively, it could be good if the user could override the default version detection after the foo*.war resource has been found, but before it is finally added to the inventory.